Access rejustify with R
R is one of the most commonly used languages by data scientists and industry practicioners. It is no surprise that rejustify API can be accessed directly from R by installing the specially designed package. Quick and easy installation process requires an e-mail address and a token, which you can get by creating a free account. While the free account offers basic access to the rejustify API, the most practical functionality can be unlocked with a premium or enterprise access.
The guide below demonstrates the basic package installation process and the most commonly used rejustify API functions. The full description of the functions and their parametrization can be found in the official package description.
- Installation
- Analyze data
- Adjust structure
- Fill the data
- Visualize matching procedures
- All-in-one tutorial
1. Installation
The rejustify R package can be downloaded and installed directly from github. To load it smoothly, make sure you have package remotes.
install.packages("remotes") #just in case
remotes::install_github("rejustify/r-package")
library(rejustify)The API authorization is achieved through e-mail and token authentication. The e-mail corresponds to the primary e-mail of the account. Each account is assigned a unique token, which can be seen after signing in.
The rejustify API access is determined in two steps. Firstly, the details of the curl connection must be set in the R console with function setCurl(). Secondly, the account details are passed onto the package with a function register().
setCurl()
register(token = "YOUR_TOKEN", email = "YOUR_EMAIL")All set, you're ready to access the rejustify engine!
In the case you're connecting through a proxy server, you may specify the details of the connection directly in the setCurl() function.
setCurl(proxyUrl = "PROXY_ADDRESS", proxyPort = 8080)2. Analyze data
analyze() is one of the three core functions of the R package which offers a direct access to the analyze endpoint. Its goal is to provide the basic characteristics of the data set and provide data suggestions for empty dimensions, which can be directly used by the fill endpoint (see below). Function analyze() recognizes any data frame or matrix data representation. By default it expects a vertical, i.e. colum-oriented data, but row-oriented data sets can be analyzed with shape='horizontal' option.
By default analyze() will not store any data it handles. However, the full functionality and predictive power of the API can be vastly improved by enabling tracking the call history. The Machine Learning engine can be switched on by learn=TRUE option.
In an example below we create a mock data set with three columns with headers year, country and gross domestic product. The first two contain basic year and country dimesnions, whereas the last column is empty - this is the column which will be rejustified.
#sample data set
df <- data.frame(year = c("2009", "2010", "2011"),
country = c("Poland", "Poland", "Poland"),
`gross domestic product` = c(NA, NA, NA),
check.names = FALSE, stringsAsFactors = FALSE)
st <- analyze(df, learn = TRUE)analyze() returns three important pieces of information:
- descriptive details: dimension id, column id, dimension name and if a column is empty or not,
- basic properties of the dimensions: classes, features, cleaners, formats and the corresponding classification accuracy,
- resources which fit best into the empty dimensions of the data based on the data structure and history.
Currently, rejustify distinguishes between 6 classes: general, geography, unit, time, sector and number. They describe the basic characteristics of the values, and are further used to propose the best transformations and matching methods for data reconciliation in the fill endpoint. Classes are further supported by features, which determine these characteristics in greater detail, such as class geography may be further supported by feature country. Cleaner contains the basic set of transformations applied to each value in a dimension to retrieve machine-readable representation. For instance, values y1999, y2000, ..., clearly correspond to years, however, they will be processed much faster if stripped from the initial y character, such as ^y. Cleaner allows for basic regular expressions. Finally, format corresponds to the format of the values, and it is particularly useful for time-series operations. Format allows the standard date formats (see ?as.Date in R console).
For instance, the data from the example above can be assigned the following structure (in the form of a data frame).
id column name empty class feature cleaner format p_class provider table p_data
1 1 year 0 time year <NA> %Y 1.00 <NA> <NA> NA
2 2 country 0 geography generic <NA> <NA> 0.40 <NA> <NA> NA
3 3 gross domestic product 1 general <NA> <NA> <NA> 0.75 IMF WEO 0.43. Adjust structure
It is possible that the rejustify engine will not provide the suggestions the User had in mind initially. While it is possible to adjust each element in the structure manually, adjust() offers a intuitive and tidy way of changing single or multiple elements in one line. The functions expects which dimensions are to be changed, by either dimension id or column id (if both are given the preference is given towards the latter), and the items which are to be replaced (in the form of a list).
For the example above, feature generic is not the most precise representation of the dimension. Let's make it more accurate by changin it to geography.
st <- adjust(st, id = 2, items = list('feature' = 'country'))id column name empty class feature cleaner format p_class provider table p_data
1 1 year 0 time year <NA> %Y 1.00 <NA> <NA> NA
2 2 country 0 geography country <NA> <NA> -1.00 <NA> <NA> NA
3 3 gross domestic product 1 general <NA> <NA> <NA> 0.75 IMF WEO 0.4Similarly, one may want to switch from provider/table IMF/WEO to the data from Eurostat given in AMECO/HVGDP table. The full list of our resources, including data providers and tables, can be found in our repository browser.
st <- adjust(st, column = 3, items = list('provider' = 'AMECO', 'table' = 'HVGDP'))id column name empty class feature cleaner format p_class provider table p_data
1 1 year 0 time year <NA> %Y 1.00 <NA> <NA> NA
2 2 country 0 geography country <NA> <NA> -1.00 <NA> <NA> NA
3 3 gross domestic product 1 general <NA> <NA> <NA> 0.75 AMECO HVGDP -1Upon changes in structure, the corresponding p_class or p_data will be set to -1. This is the way to inform API that the original structure has changed and in case the learning option is enabled, the new values will be used to train the AI algorithms. If learn=FALSE, information will not be stored by the API but the changes will be recognized in the current API call.
4. Fill the data
fill() aims at filling the missing data for each empty dimension in the original data set by data points delivered by provider/table. Rejustify engine calls the submitted data set by x and any server-side data set by y. The corresponding structures are marked with the same principles, as structure.x and structure.y, for instance. The principle rule of any data manipulation is to never change data x (except for missing values), but only adjust y.
There are two main elements which need to be defined for this process:
- matching keys - which elements from x and y are to be matched together and which matching method is the most appropriate,
- default values for non-matched dimensions of y.
If not defined explicitly, the engine will suggest the best-fitting matching keys and default values.
To continue the example from above, fill() needs at least the original data set and structure.
rdf <- fill(df, st)In effect, fill() substitutes missing values in gross domestic column column by GDP figures for Poland in years 2009-2011 from AMECO/HVGDP table. The values are determined by default specification as an index (PPS: EU-15 = 100).
Original data set
year country gross domestic product
2009 Poland NA
2010 Poland NA
2011 Poland NARejustified data set
year country gross domestic product
2009 Poland 53.5585
2010 Poland 56.6635
2011 Poland 59.28214.1. Matching keys
The elements in keys are determined based on information provided in data x and y, for each empty column. The details behind both data structures can be visualized by structure.x and structure.y. The latter in our example corresponds to the AMECO/HVGDP table which will be used to fill the missing values in column.id.x=3.
id column name empty class feature cleaner format p_class provider table p_data
1 1 Frequency 0 general <NA> <NA> <NA> 1 <NA> <NA> NA
2 2 Unit 0 unit generic <NA> <NA> 1 <NA> <NA> NA
3 3 Country 0 geography country <NA> <NA> 1 <NA> <NA> NA
4 4 Time Dimension 0 time year <NA> %Y 1 <NA> <NA> NA
5 5 Primary Measure 0 numeric generic <NA> <NA> 1 <NA> <NA> NAMatching keys are given consecutively, i.e. the first elements in id.x and name.x correspond to the first elements in id.y and name.y. Dimension names are given for the better readability of the results, however, they are not necessary for the engine.
..$ id.x : int [1:2] 1 2
..$ name.x : chr [1:2] "year" "country"
..$ id.y : int [1:2] 4 3
..$ name.y : chr [1:2] "Time Dimension" "Country"
..$ class : chr [1:2] "time" "geography"
..$ method : chr [1:2] "time-matching" "synonym-matching"
..$ column.id.x : int 3
..$ column.name.x: chr "gross domestic product"Currently, the rejustify engine supports 6 matching methods: synonym-proximity-matching, synonym-matching, proximity-matching, time-matching, exact-matching and value-selection, which are given in a diminishing order of complexitiy. synonym-proximity-matching uses the proximity between the values in data x and y to the coresponding values in rejustify dictionary. If the proximity is above accuracy threshold and there are values in x and y pointing to the same element in the dictionary, the values will be matched. synonym-matching and proximity-matching use a similar logic either of the steps described for synonym-proximity-matching. time-matching aims at standardizing the time values to the same format before matching. For proper functioning it requires an accurate characterization of date format in structure.x (structure.y is already classified by rejustify). exact-matching will match two values only if they are identical. value-selection is a quasi matching method which for single-valued dimension x will return single value from y, as suggested by default specification. It is the most efficient matching type for dimensions which do not show any variability.
4.2. Default values
Default values are used to lock dimensions in y which will be not used for matching against x. Each empty column to be filled, characterized by column.id.x, must contain description of the default values. The default values include both codes and labels, however, only the former are relevant for rejustify engine.
code_default label_default
Frequency a Annually
Unit pps-eu-15-100 (PPS: EU-15 = 100)
Country aus Australia
Time Dimension latest Label not available
Primary Measure <NA> Label not available5. Visualize matching procedures
Data sets supported by rejustify can be quite complex. It is useful therefore to verify if the proposed matching procedures satisfy your preferences. To make it easier, we offer vis() function. When applied to an object returned by fill(), it will provide a visual interpretation of the object. Let's continue with the main example above.
vis(rdf)Function vis() returns two elements: graphical and descriptive. The former offers an illustration of the matching procedure for column gross domestic product. The two data sets are displayed in two columns. Each block in a column correspnds to a dimension. Colors depict if the dimension is used for matching, with matching methods described in the legend. If the dimension is locked or is matched by value-selection method, it will display the default code below the dimension name.
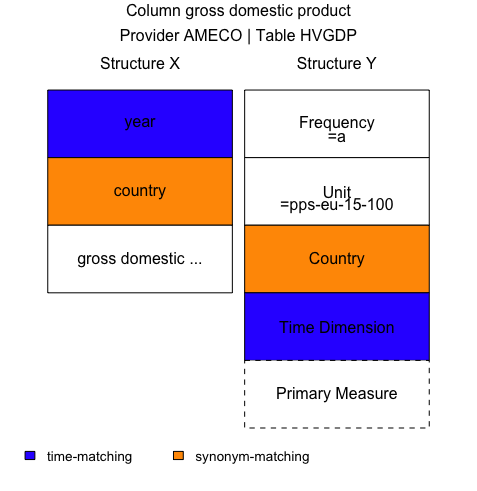
The descriptive element provides extra information that may turn useful when interpreting the matching results, like code and label definitions.
Displaying matching procedures for column 3: gross domestic product
Default matching values:
a = Annually
pps-eu-15-100 = (PPS: EU-15 = 100)
To browse all labels: labels('AMECO','HVGDP')